
在科技蓬勃发展的浪潮中,人工智能已成为推动时代变革的核心力量。历经 60 余载砥砺前行,人工智能在算法精进、计算能力飞升与数据海洋的拓展中斩获关键突破,却依旧站在发展初级阶段的起点,前方是无垠的理论创新与技术变革的浩瀚宇宙,背后则是广袤的应用拓展天地。当下我国人工智能发展态势恰似一幅蓬勃向上的画卷,“高度重视,态势喜人,差距尚存,前景璀璨”精准勾勒出其轮廓。
国家战略层面,党中央、国务院对人工智能发展倾尽全力支持。2017 年 7 月,国务院重磅发布《新一代人工智能发展规划》,将其擢升至国家战略高度精心部署。习近平总书记在十九大、两院院士大会等重大场合多次殷切强调加速推进新一代人工智能发展,为其铺就坚实政策基石。
一、专用与通用人工智能的两极分化
(一)专用人工智能的辉煌成就
从应用维度剖析,人工智能可清晰划分为专用与通用两大阵营。专用人工智能剑指特定任务,如下围棋的阿尔法狗(AlphaGo),其任务专一、需求澄澈、边界分明、领域知识深厚、建模简易,在局部智能测试中屡破人类极限,AlphaGo 于围棋赛场折桂、图像识别与人脸识别技术超越人类感知、皮肤癌诊断精准度比肩专业医生,恰似璀璨星辰照亮人工智能苍穹。
(二)通用人工智能的漫漫征途
通用人工智能则似萌芽待放之花,尚在起步探索阶段,研发与应用之路漫漫修远。当前人工智能系统在信息感知、机器学习等“浅层智能”领域大步迈进,然而于概念抽象、推理决策等“深层智能”范畴却举步维艰,总体发展水平仍有巨大跃升空间。
展望未来,人工智能恰似燎原之火,将随技术迭代与应用场景拓展燃遍诸多领域,“智能+X”范式日臻成熟,深度渗透融合各行各业,重塑社会发展格局,奏响第四次技术革命最强音。
二、深度学习:突破传统机器学习瓶颈的利器
回溯往昔,传统机器学习面对小规模数据尚可周旋,涉足图像识别时却深陷特征提取困境。彼时依赖人工标注设计特征,过程繁琐耗时,智能水平受限,难以招架复杂任务与海量数据冲击。
深度学习应运而生,宛如救星降临。作为机器学习分支,其精髓在于构建多层隐藏层神经网络,凭借海量数据锤炼模型自动萃取高阶特征,革新传统特征提取范式,凸显特征学习核心地位,强力驱动人工智能飞跃。
20 世纪 90 年代,Geoffrey Hinton 教授团队勇闯深度学习无人区,虽初期屡战屡败,却矢志不渝。2006 年 7 月,其在《科学》杂志发表论文,以创新方法攻克梯度消失难题,点燃深度学习研究新烽火。此后,2011 年激活函数革新缓解梯度困境,微软语音识别领域创新应用为深度学习正名。
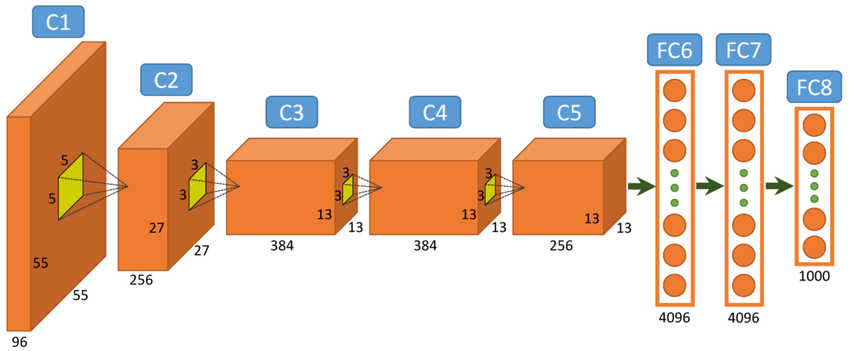
2012 年至 2015 年,深度学习于计算机视觉领域连创佳绩。Hinton 团队 AlexNet 模型借 ImageNet 数据与 GPU 算力,在 ImageNet 大赛中使图像分类 Top5 错误率从 26.2%锐减至 15.3%夺冠,惊爆学术界。随后 Fergus 团队、Google 团队、微软亚洲研究院团队接力优化,四年内将错误率压低至 3.6%,深度学习浪潮自此汹涌全球。

2016 至 2017 年,AlphaGo 人机大战轰动世界,深度学习声名远扬,全球科研精英纷至沓来,产学研协同共进,推动技术高歌猛进。其崛起与高性能计算、大数据技术相辅相成,GPU 集群与海量数据为深度卷积神经网络筑牢根基,众多深度网络及复合型网络竞相涌现。
深度循环与递归网络别具一格,专注序列向量输入,借循环机制挖掘上下文逻辑,于自然语言处理领域大显身手,拓展深度学习“深度”至时间维度,丰富其内涵与应用疆域。
三、大语言模型:自然语言处理的智慧引擎
大语言模型(LLM)无疑是人工智能舞台的耀眼明星,依托深度学习与神经网络技术,解锁人类语言理解与生成奥秘,在文本处理各领域纵横捭阖。
LLM 本质是经海量文本数据洗礼、参数亿万的深度神经网络模型,可精准预测下文或创作文本,深度洞察语言语法、语义与上下文关联,构筑完备语言知识大厦。
其核心技术多元且精妙。早期统计语言模型如 n-gram 模型受数据稀疏与计算复杂掣肘。2003 年神经网络语言模型登场,词嵌入技术革新语义捕捉方式。RNN 携时序处理能力入局却遇梯度难题,LSTM 与 GRU 披荆斩棘化解困境。2017 年 Transformer 架构横空出世,凭借注意力机制独辟蹊径,重塑自然语言处理生态,加冕主流架构桂冠。
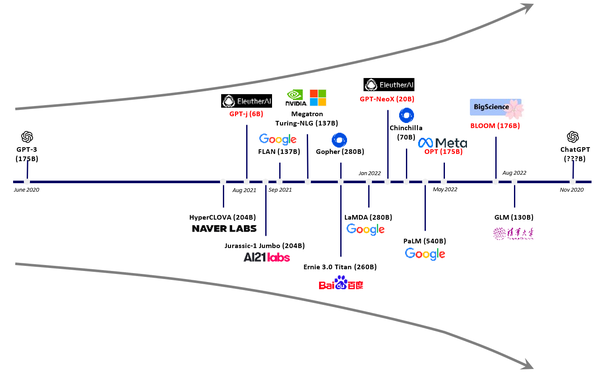
科技巨头竞相发力,2018 年 Google BERT 预训练微调范式提升多项 NLP 性能;OpenAI 同年推出 GPT,GPT-2、GPT-3 接踵而至,参数规模呈指数攀升,生成能力与泛化性能卓越非凡。2022 年末 ChatGPT 引爆全球,多轮对话流畅自如;2023 年 GPT-4 惊艳亮相,多模态理解技惊四座,基准测试屡创佳绩。LLM 应用广泛,新闻创作、文学创作、翻译优化、智能客服、代码生成、教育辅助无所不能,全方位革新生活工作体验。
然而,大语言模型发展亦遇荆棘。数据隐私、系统偏见、决策可解释性迷雾重重,训练资源能耗高昂令人咋舌。未来需聚焦模型压缩、知识蒸馏等技术攻坚,强化内容管控,借强化学习(尤其是 RLHF)校准价值航向,确保模型为人类福祉添砖加瓦,引领人工智能在自然语言处理领域乘风破浪、稳健前行。

