


论文题目: CETN: Contrast-enhanced Through Network for Click-Through Rate Prediction
论文作者:李鸿皓,桑磊,张逸,张旭云,张以文(通讯作者)
论文链接:https://dl.acm.org/doi/10.1145/3688571
代码链接:https://github.com/salmon1802/CETN
1. 背景介绍
在特定环境(如网站和应用程序)下,准确预测用户对项目(如产品、电影和广告)的响应在商业个性化推荐系统中起着至关重要的作用。一方面,绝大多数商业推荐系统的收入与用户点击率(CTR)息息相关。另一方面,用户满意度与推荐系统的性能指标密切相关。一个性能良好的点击率预测模型有助于迅速识别用户兴趣,从而提升用户体验。
然而,许多现有的点击率预测模型所建立的语义空间较为狭隘,无法有效的捕获高质量特征交互。出现这种缺陷的原因主要有以下三点:
(1)语义空间分割不力:大多数具有并行结构的 CTR 模型在其并行子组件之间共享嵌入层,并直接将所有特征嵌入拼接后作为模型的输入。这种做法使得来自不同语义空间的特征交互信息过于一致,而依靠子组件独立提升被捕获信息的多样性无疑是低效的。
(2)多语义空间中的监督信号不足:基于并行结构的点击率预测模型通常需要一个融合层来聚合各个子组件捕获的特征交互信息,以获得最终预测结果,并且通常使用 1-bit的点击信号进行训练。因此,在信息聚合之前,各个子组件之间缺乏交流和有效的监督信号。这可能会阻碍模型捕获高质量、非冗余的信息,并降低捕获信息的多样性。
(3)多语义空间中的过量噪声:当模型在追求语义空间多样性的同时,也不可避免地面临着被捕获信息“差异过大 ”的挑战。这可能会导致模型在融合层中聚集大量噪声信号,从而降低模型性能。因此,确保各个子组件捕获信息的一致性也至关重要。
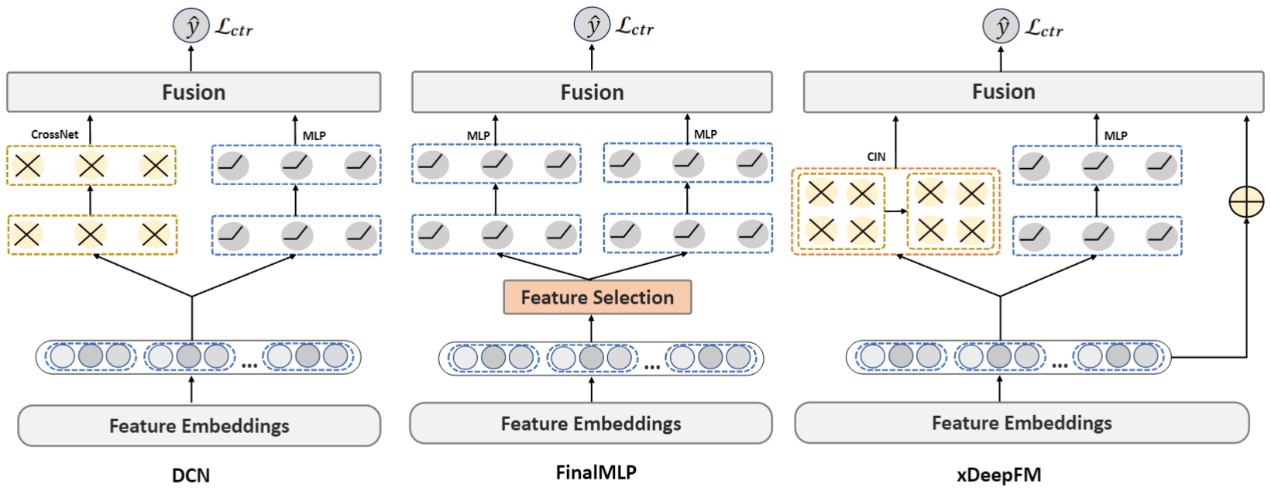
图1 具有并行结构的三种基线模型结构:DCN、FinalMLP 和 xDeepFM
为了更详细地解释上面提出的三个缺陷,如图 1 所示,本文以三个强大的基线模型为例。就DCN而言,它的两个子组件共享一个嵌入层,并通过 CrossNet 显式捕捉低阶特征交互,通过 MLP 隐式捕捉高阶特征交互。在融合层中,其使用简单的求和来汇总来自两个语义空间的信息。然而,这种直接的信息捕捉方法无法解决本文发现的三个缺陷。FinalMLP 首先使用特征选择层分割两个语义空间,确保这些空间所含信息的多样性,随后采用两个 MLP 来隐式捕捉每个语义空间中的特征交互信息。最后,在语义空间中引入显式乘积操作。该模型解决了语义空间缺乏分割的问题,确保了这些空间的信息多样性,并取得了出色的性能。但是,它在每个语义空间内都缺乏有效的监督信号,无法使MLP通过自监督的方式捕捉语义空间的多样化信息。同时,它也缺乏对主语义空间和辅助语义空间的区分,无法保证整个模型捕获信息的同质性。同样,xDeepFM 将数据分为三个语义空间,并以更复杂的方式建立特征交互模型,以确保捕获的特征交互信息的多样性。然而,它也面临着与 DCN 类似的挑战,即无法平衡被捕获信息的多样性和同质性。
为了解决并行子组件之间普遍存在的上述三个问题,本文引入了一种新的点击率预测模型,命名为 “对比增强贯通网络(CETN)”。具体来说,本文引入了噪声增强与自监督信号以提高被捕获到的特征交互信息的多样性,同时利用具有不同激活函数的多个Key-Value Blocks作为模型的并行子组件。此外,为了解决多样性带来的问题,本文提出了一种贯通连接(可视为残差连接的横向变体),以确保各个子组件所捕获信息的同质性。在融合层之前,本文在每个语义空间内的自监督学习过程中引入了 “只计算分母的InfoNCE损失”(Denominator-only InfoNCE,Do-InfoNCE)和余弦损失。在四个真实世界数据集上进行的广泛实验表明,简单而有效的CETN模型在 AUC 和 Logloss 方面始终优于 20 个基线模型。
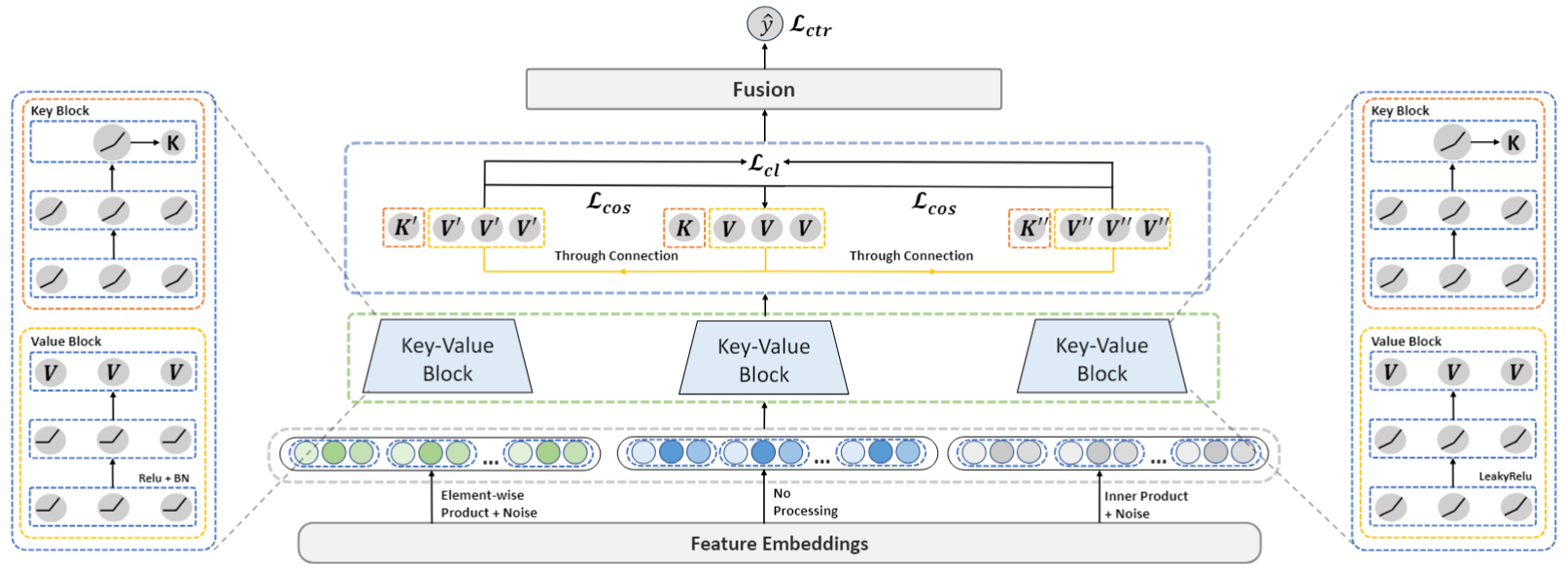
图2 CETN模型总览
2. 方法
本文将捕获高质量特征交互信息作为目标,提出了一种平衡特征表征之间多样性与同质性的自监督策略。本文提出的CETN的模型框架图如图2所示,其输入是用户资料、项目属性、交互环境上下文三类特征的嵌入。我们称这种数据为多字段分类数据,其样本示例如表1所示。
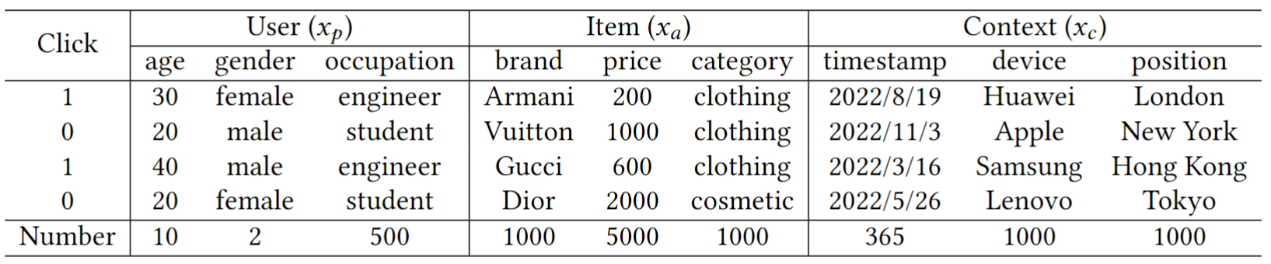
表1 多字段分类数据示例。
首先,本文探讨了如何从多语义空间简单而高效地捕捉特征交互。考虑到 MLP 的高效性和灵活性,以及其良好的并行性,本文将其作为各语义空间模型的子组件,以捕获各语义空间中的信息。同时在原有语义空间的基础上,本文使用内积和哈达玛积进一步切分出多个辅助语义空间:另一方面,由于多个语义空间的存在,需要去选择哪些空间是更有效的,因此本文进一步的提出了Key-Value Block来作为模型子组件的基本构成模块。本文将该模型称为简单多头网络 (simMHN),其架构图如图3所示。通过对simMHN进行了初步性能评估,其结果如表2所示。
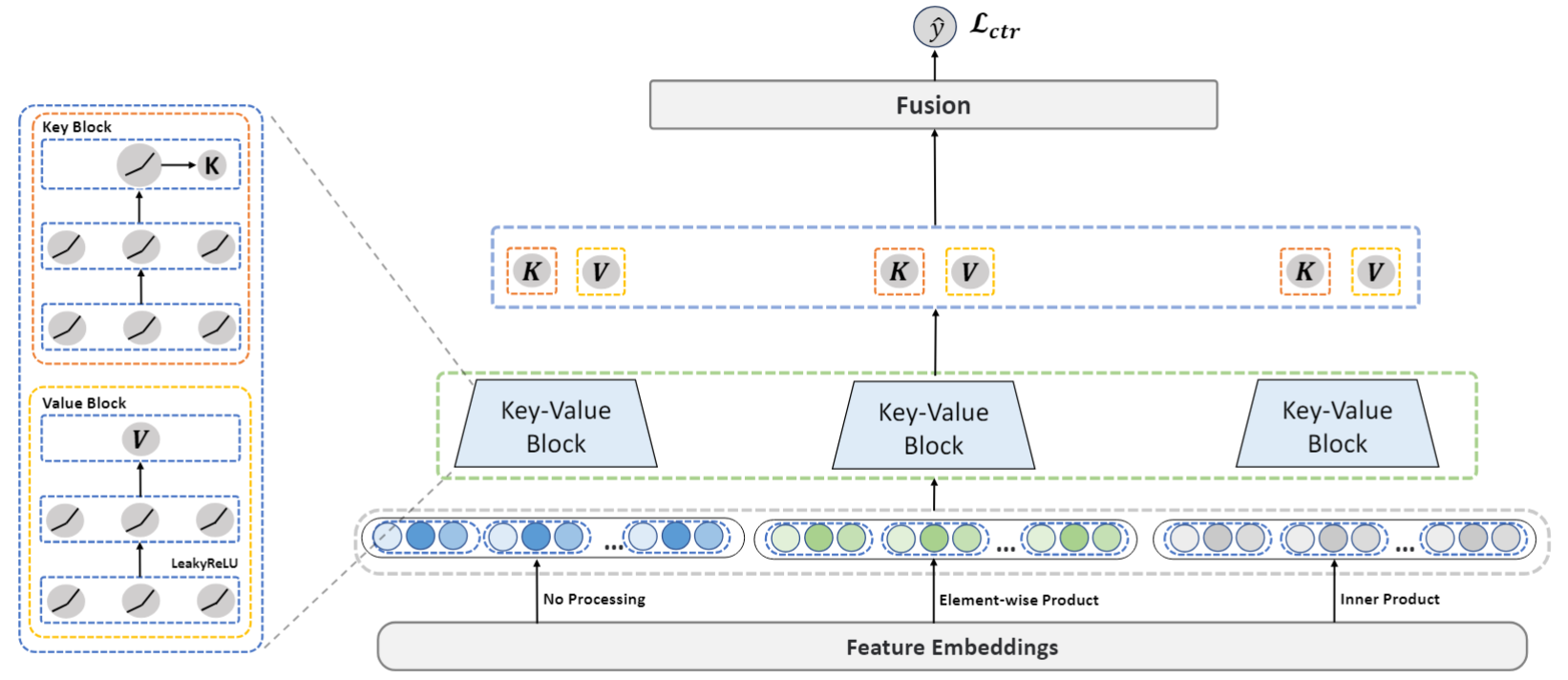
图3 simMHN模型总览。
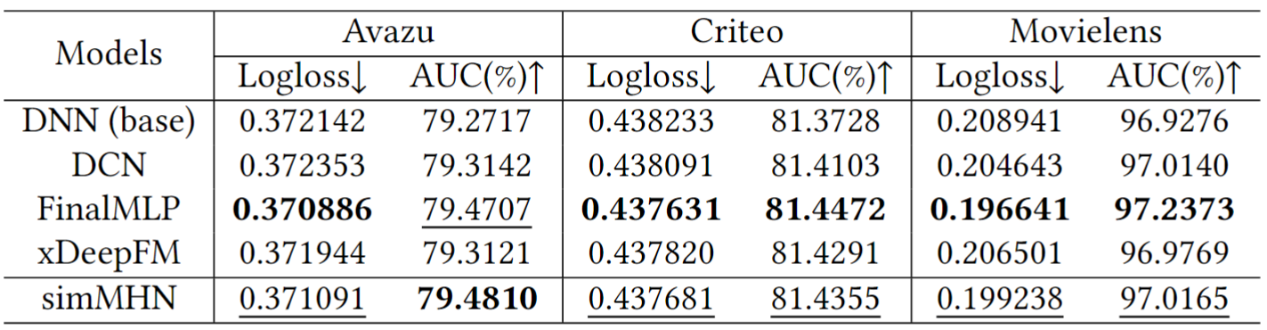
表2 simMHN与三个强基线模型的性能比较。。
从表二中不难发现,使用这种简单的架构虽然只解决了语义空间分割不力的问题,但是即可达到与SOTA性能相当的水准。因此,本文进一步的尝试对其进行性能优化。
正如之前所说,本文进一步探究了如何改进模型所捕获信息的多样性。具体地说,本文使用了为特征嵌入引入额外噪声并使用“只计算分母的InfoNCE损失”(Denominator-only InfoNCE,Do-InfoNCE)来迫使多个子组件之间捕获到的特征交互信息更加不同:

另一方面,为了解决一味追求多样性所带来的噪声问题,本文引入了与其相反的概念,即同质性。因此,本文进一步探究了如何确保模型所捕获信息的同质性。具体地说,本文使用贯通连接与余弦损失来实现这一目的。贯通连接可以被视为一种横向的残差连接,这使得辅助语义空间对应的Key-Value Block所捕获的信息建立在主语义空间之上,同时利用余弦损失来控制辅助语义空间与主语义空间中被捕获信息的差异。贯通连接的结构图如图4所示。
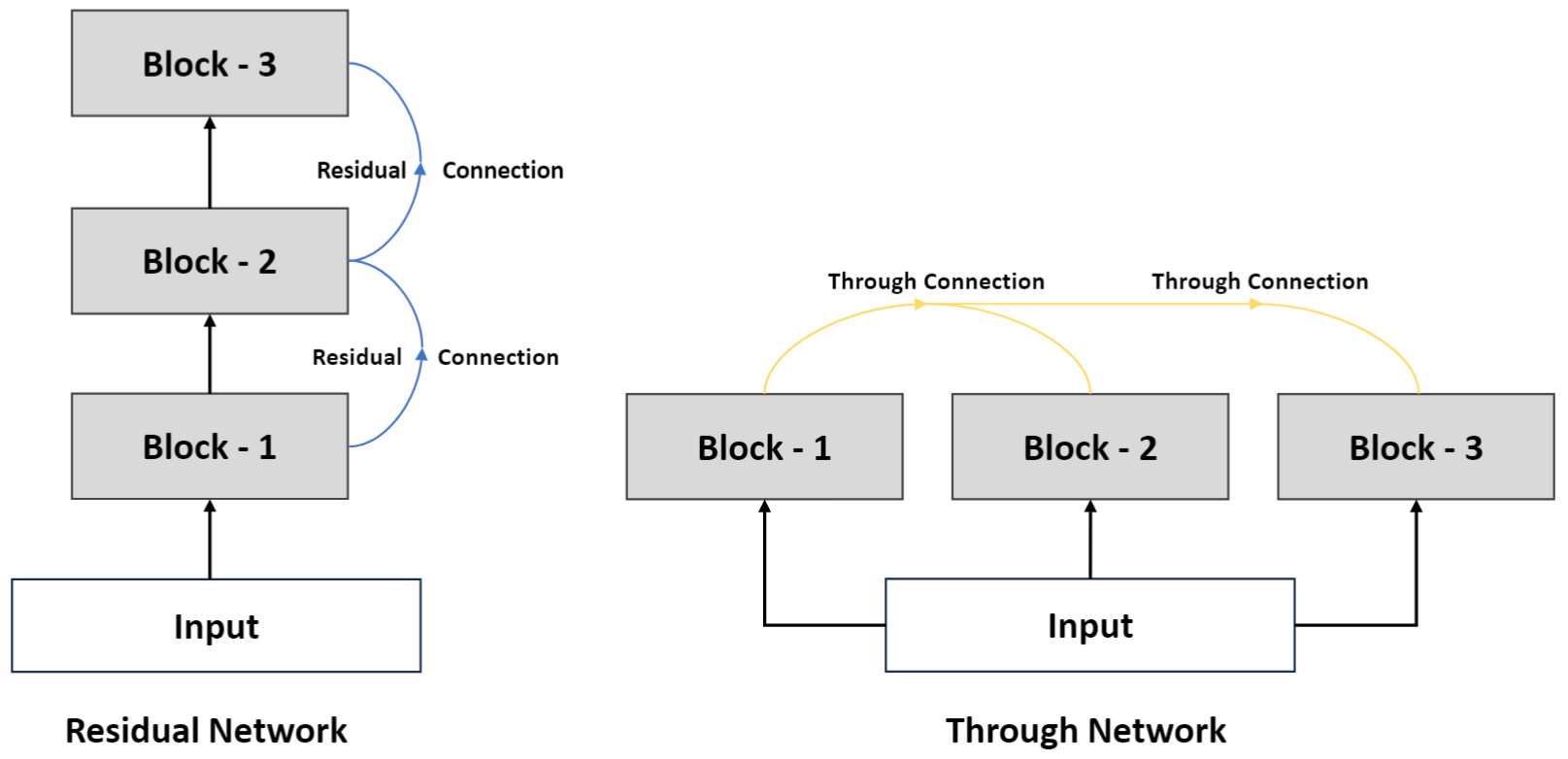
图4 贯通连接和残差连接之间的关系
本文通过以上方式来平衡模型在多个语义空间中所捕获信息的多样性与一致性。从图5中直观的观察到,过度的多样性与同质性带来的坏处:过多的多样性会为模型引入过多的噪声,而过多的同质性会使模型捕获的信息存在冗余,而只有当被捕获的信息达到一种平衡时,模型性能的提升才会达到峰值。
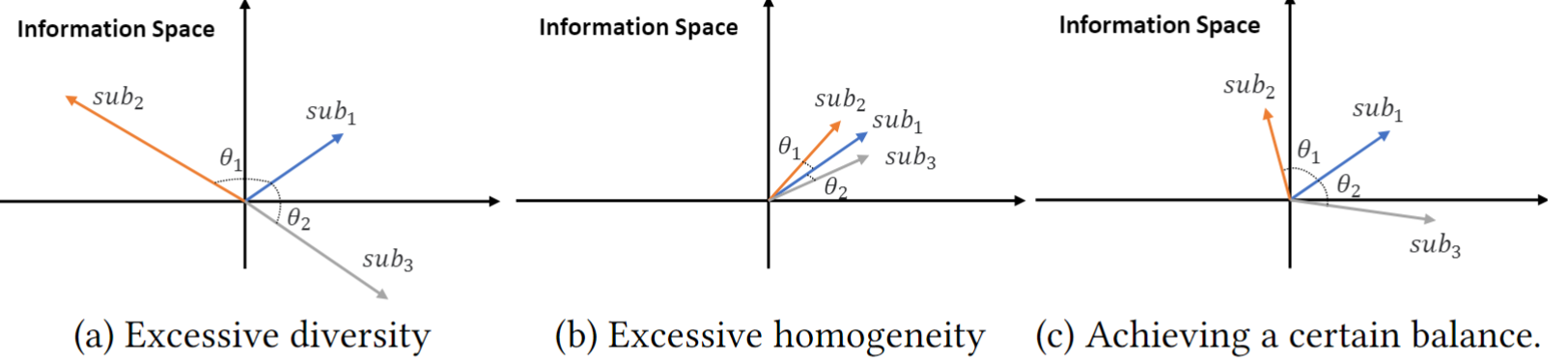
图5 多样性和同质性的说明。
3. 实验
在四个被广泛使用的CTR预测数据集上验证了CETN的有效性。指标采用Logloss和AUC。实验结果如表3与表4所示。
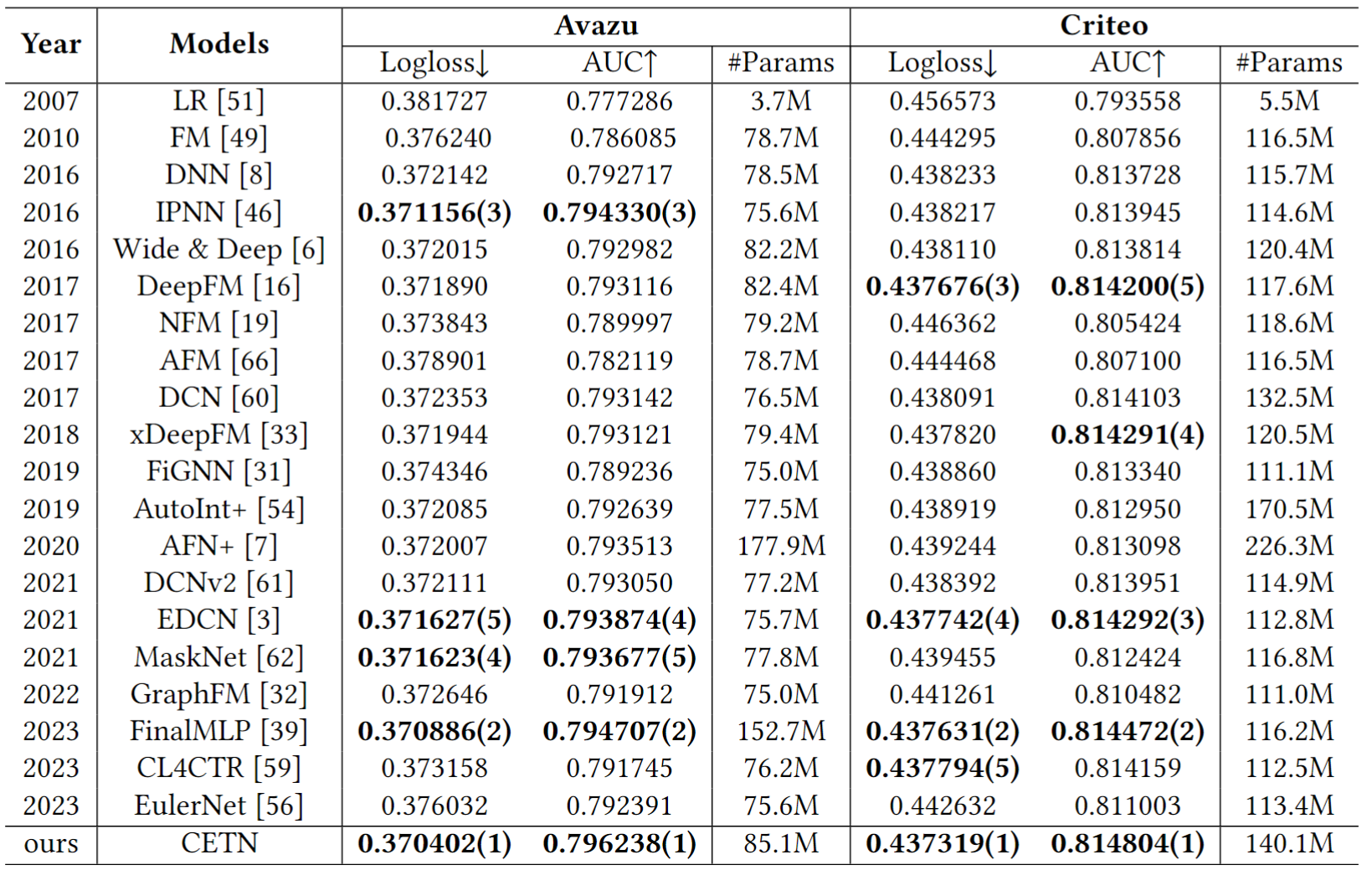
表3 不同 CTR 预测模型的性能比较。
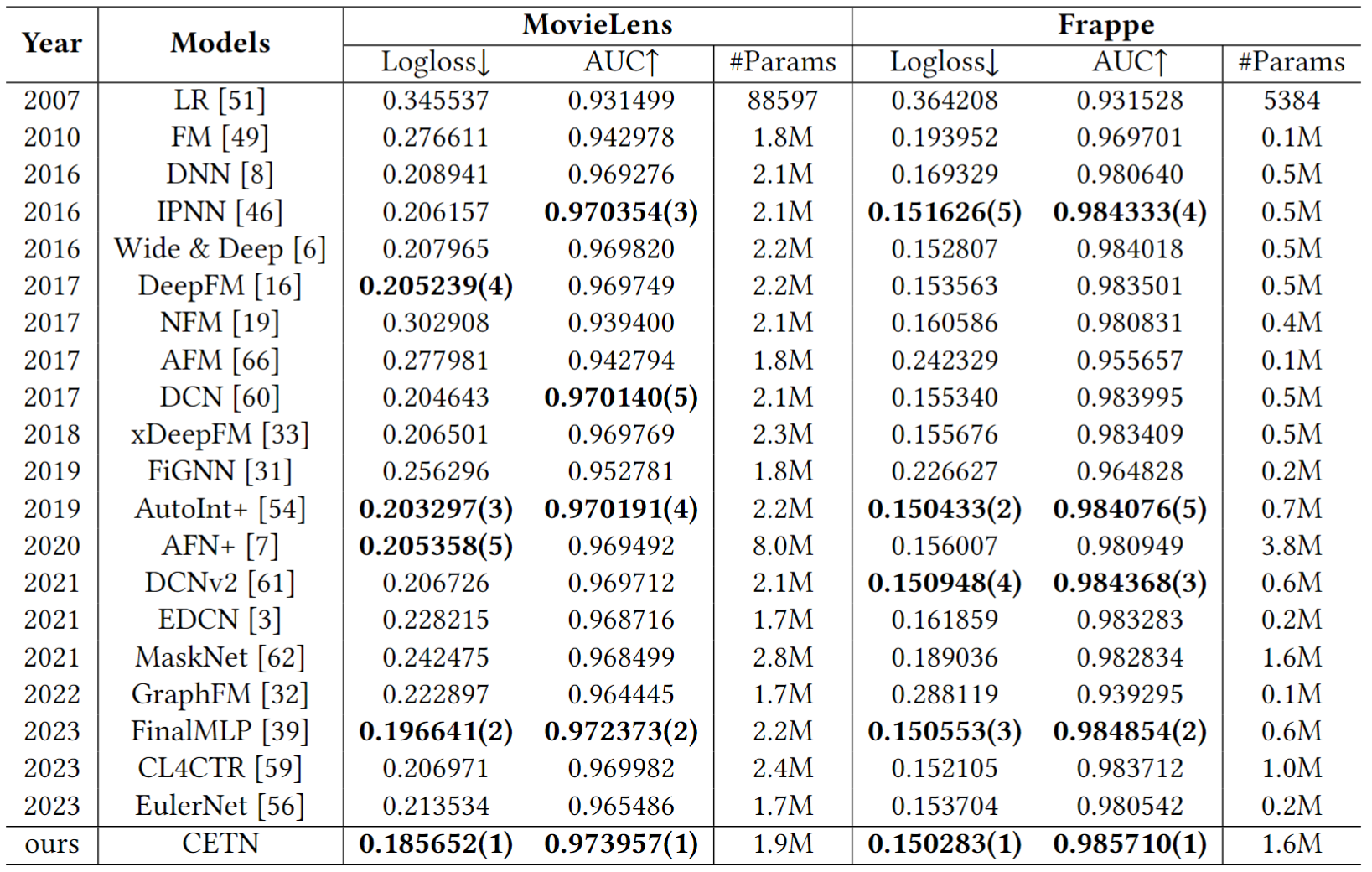
表4 不同 CTR 预测模型的性能比较。
在所有设置和数据集上,CETN优于所有对比方法。具体而言,与最佳基线模型相比,CETN 在四个数据集上的 AUC 分别比 FinalMLP 提高了 0.52%、0.11%、0.34% 和 0.18%,同时 Logloss 也相应降低了 0.13%、0.07%、5.59% 和0.1%。值得注意的是,与复杂的显式特征交互网络相比,我们所提出的 CETN 模型只是将对比学习的概念整合到了simMHN 中,从而有效提高了其捕获特征交互信息的能力。因此,这进一步证明了平衡多样性与同质性是有必要的。
4.结论
本文重新审视了从多个语义空间有效捕捉特征交互信息的问题,并将多个Key-Value Block作为并行的子组件,组成了简单多头网络(simMHN)。然后,围绕多样性和同质性这两个互补原则进一步增强了simMHN,本文提出了一种新的简单有效的 CTR 模型,即对比增强型贯通网络(CETN)。其以 simMHN 为基础,利用对比学习和直通连接进一步捕捉高质量的特征交互信息。在四个基准数据集上的实验结果验证了本文提出的模型的有效性。
供稿:李鸿皓,博士研究生,安徽大学计算机科学与技术学院

